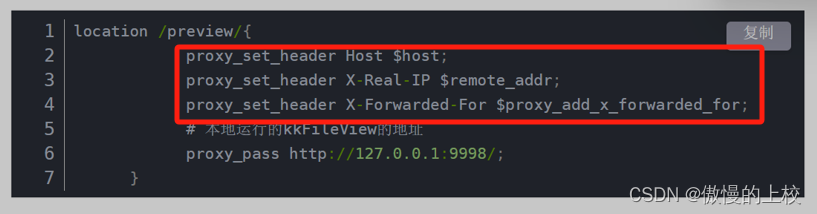
使用accelerator还有很方便的加速并行训练,而register_for_checkpointing,可以帮助我们管理需要在训练过程中保存的变量,可如果在训练过程中发现如初始化设置的epoch等变量还不足以让模型收敛,这时要改动scheduler或者optimizer会发现没法修改或者替换,但我们又舍不得当前训练出来的模型。
这时我们可以先把模型保存下来。
accelerator.wait_for_everyone()
accelerator.save_model(model,"model_path",safe_serialization=False)然后在使用accelerator.prepare前加载该模型。
model.load_state_dict(torch.load("model_path/pytorch_model.bin"))在之后的代码里不要读取accelerator建立的存档,重新初始化optimizer等变量集合就行。